
Interesting how they have kept their ops team the same but now run an entire datacentre.
Overworked teams? I just can’t see how this is possible.
Not defending cloud hosting/costs etc. You generally pay more for cloud to then not have to deal with hardware maintenance, datacentre management. I didn’t see this directly in their post. Other than keeping the same size Ops team
I’m running both physical hardware and cloud stuff for different customers. The problem with maintaining physical hardware is getting a team of people with relevant skills together, not the actual work - the effort is small enough that you can’t justify hiring a dedicated network guy, for example, and same applies for other specialities, so you need people capable of debugging and maintaining a wide variety of things.
Getting those always was difficult - and (partially thanks to the cloud stuff) it has become even more difficult by now.
The actual overhead - even when you’re racking the stuff yourself - is minimal. “Put the server in the rack and cable it up” is not hard - my last rack was filled by a high school student in a part of an afternoon, after explaining once how to cable and label everything. I didn’t need to correct anything - which is a better result than many highly paid people I’ve worked with…
So paying for remote hands in the DC, or - if you’re big enough - just order complete racks with racked and pre-cabled servers gets rid of the “put the hardware in”.
Next step is firmware patching and bootstrapping - that happens automatically via network boot. After that it’s provisioning the containers/VMs to run on there - which at this stage isn’t different from how you’d provision it in the cloud.
You do have some minor overhead for hardware monitoring - but you hopefully have some monitoring solution anyway, so adding hardware, and maybe have the DC guys walk past and inform you of any red LEDs isn’t much of an overhead. If hardware fails you can just fail over to a different system - the cost difference to cloud is so big that just having those spare systems is worth it.
I’m not at all surprised by those numbers - about two years ago somebody was considering moving our stuff into the cloud, and asked us to do some math. We’d have ended up paying roughly our yearly hardware budget (including the hours spent on working with hardware we wouldn’t have with a cloud) to host a single of one of our largest servers in the cloud - and we’d have to pay that every year again, while with our own hardware and proper maintenance planned we can let old servers we paid for years ago slowly age out naturally.
Thank you for the very detailed response!
They’re using a third party called deft to manage the hardware. Which is a reasonable middleground between cloud and self-operated, the more I think about it.
I haven’t seen a lot of info on what the cost of that management is though but it’s likely to be leagues less than AWS/GCP
It’s not just the hardware. “The cloud is expensive” is usually touted by people not understanding why managed services (like Aurora RDS and OpenSearch as suggested in the article) ‘cost more than running it themselves’ by not accounting the management costs.
A database service needs management not only in hardware (I.e. replace dead drives) but also in software (I.e. monitor cluster performance, tweak system settings to fit usage pattern, manage cluster health, etc etc). These management requires time from the ops team, often in multiple roles like SysAdmin, DBA, and Ops engineers. Fact that they claim to have moved to their own hardware without being on new talents to their ops team makes it questionable as to whether or not they actually understand the cost and If they’re overworking their existing ops team.
Or it could be that they haven’t run into problems yet. If you overbuild your hardware or your software is efficient enough, you don’t need as much tweaking.
It’s questionable, but I don’t think implausible.
“yet” is the keyword there for sure. It’s not a matter of if, but a matter of when. Even if they’re flushed with cash and grossly over provision their systems, sooner or later, a huge vulnerability will roll around and someone will need to setup / update the OS, ensuring quorum is available for their cluster, fail over traffic during update windows, etc etc etc.
The stacks are getting so insurmountably huge, it’s not possible to just drop a new cluster at their described scale without significantly increasing the workload for an existing team.
Yup. By moving out, they already let go of a lot of security services that came with their cloud subscription like CASB, automated patching, DB maintenance, security/network monitoring, etc. You have to replace all of that with people and on-prem tools/systems.
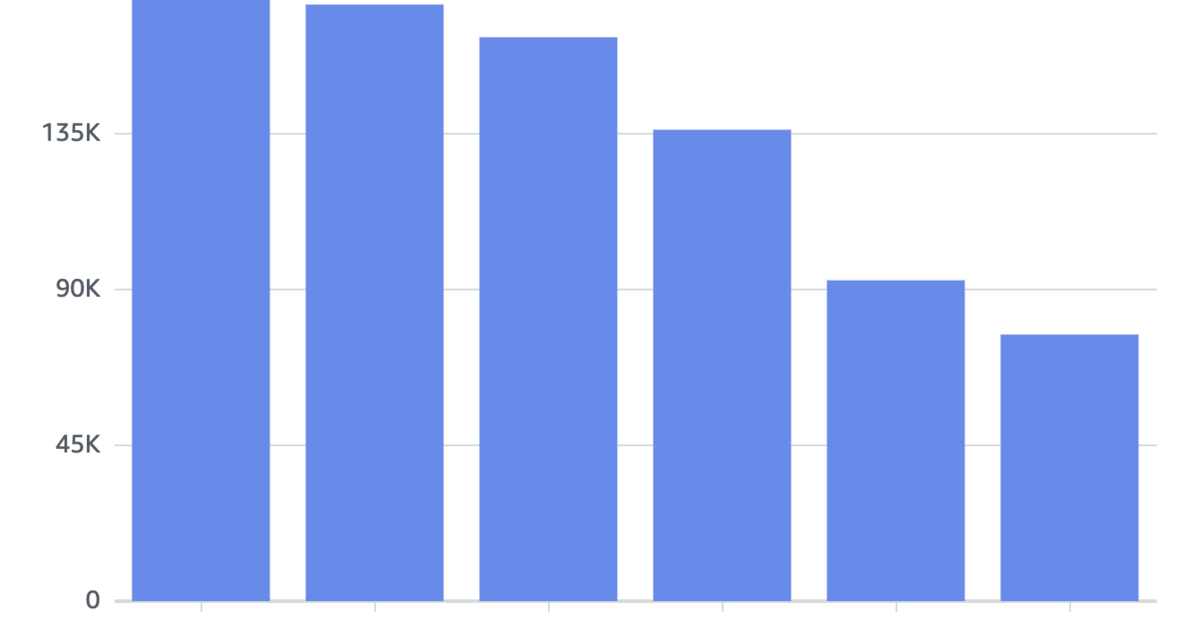
“An entire data center” is 8 rented racks in two enterprise data centers (4 racks in each). They’re paying $60K/month for racks, cooling, and location.
Warning. This site claims you’ve been blocked and asks for your email to verify you. Do not provide it. Reloaded and it worked. Just be safe out there
That isn’t happening for me, nor has it ever when I’ve visited DHH’s blog. It’s possible your browser is compromised.
I have strong privacy settings enabled. I believe it might be because they can’t fingerprint me or similar, so are checking for bot activity
That seems extremely unlikely, and almost unheard of. If I wget the page I’m a container, I get the same as in browser, so that would suggest this isn’t the case.
This didn’t happen for me
Nor i
This is quite intriguing. But DHH has left so many details out (at least in that post) as pointed out by @[email protected] - it makes it difficult to relate to.
On the other hand, like DHH said, one’s mileage may vary: it’s, in many ways, a case-by-case analysis that companies should do.
I know many businesses shrink the OPs team and hire less experienced OPs people to save $$$. But just to forward those saved $$$ to cloud providers. I can only assume DDH’s team is comprised of a bunch of experienced well-payed OPs people who can pull such feats off.
Nonetheless, looking forward to, hopefully, a follow up post that lays out some more details. Pray share if you come across it 🙏
This is part of a series of posts he has done about find out his cloud bill was stupid high because they do computationally heavy software and switching over to collocation. But the whole going from 100% cloud to colo and saving that much money is not to be scoffed at.
He does say this is an outlier and others won’t get as much roi as they have.
What always kept me off the “cloud” (other people’s computers) is not only giving up my data but giving up control on what I spend. Corporations lure you in with flashy promises and low prices, then usually over time the service gets worse the prices go higher and higher. I’m sure the cloud hosting corporations are good at pricing their services very high but not quite high enough to make most customers cancel.
That’s the thing, ‘cloud’ is just another tool in your toolbox. It’s the right tool for some workloads and the wrong one for others. The fact they’ve shifted the work to their own servers and kept the ops team suggests it was the wrong sort of workload to be in the cloud in the first place.
For a while there was an obsession with moving everything to the cloud, and that was always going to be an expensive mistake in a number of different ways. Hopefully, as the hype dies down more nuanced decisions will be made. There’s a whole gamut of options between all in the cloud and all in the data centre, and when people jump straight from one end to the other I’m put in mind of Hamlet’s quote “There are more things in heaven and earth, Horatio, / Than are dreamt of in your philosophy.” Understand your workload, understand your business’ future plans and their needs, and then make a plan, considering all the tools at your disposal.
Yeah ok well when you get ransomware’d you’re going to wish you had Cloud backups.
Ask me how I know
There are also many organizations that wish they has some local backups after their cloud service providers lost all their data. Lesson to learn: Backup properly with offline storage. Tape in a safe, maybe even off-site, etc.
So, what you’re saying is that, regardless of where you run your workloads, you should still follow the 3-2-1 rule?
3 - copies of the data. 2 - different media. 1 - offsite.
It’s funny how cloud doesn’t really change the basics of good systems administration.
Almost like a responsible modern day approach is multifaceted
How do you know?
An earwig told me
Hopefully, they place their servers at 2x the historical peak floodpoint. Or set up standby zones in different geographies in case there’s a power or network outage.
Came upon several projects where folks hadn’t…
Having your compute in “the cloud” doesn’t remove the need for a good backup strategy, it just changes how it works. Yes, disaster recover for natural disasters should be easier (OHV’s fire showed that this may not always be true). But, that doesn’t cover cases like ransomware, insider threats, data mistakes or any other case where data is corrupted/modified by mistake. You still need a plan for these cases. And cloud based backups actually make a lot of sense.
But, just because you put your backups in the cloud, doesn’t mean that your compute should be there as well. There is an advantage that your Time to Recovery is likely lower with both backups and compute in the same cloud. But, is that worth the ongoing cost of running your compute in the cloud? That needs to be considered separately. You also need to consider the cost of running on-prem versus in the cloud. If you have fairly predictable, static loads, it may be cheaper to buy and run servers yourself. For hard to predict, elastic loads, cloud may make more financial sense.
As others have said before, there was a period where companies were just going to the cloud for the sole reason that it was the popular thing to do. For some it actually made financial sense. For some, it didn’t. The OP’s article seems to be the latter.
Exactly. Use cloud for off-site backup and things that need flexibility.
You don’t need any of that to run a basic website. You can almost use an old laptop or PC for most static applications.
So how then people using this *miraculous and incredibly safe * (/s) cloud lost their data in OVH datacenter fire?
They used the cheap option without geographic mirrors.
So you say that if you don’t make an additional investment in backup infrastructure your data is at risk… Sounds pretty similar to self-hosting, doesn’t it?
More like the “cloud” provider should have multiple locations and redundancy in place.
But it’s the cloud! It can’t ever go down!
oh god, its dhh
That’s the thing, ‘cloud’ is just another tool in your toolbox. It’s the right tool for some workloads and the wrong one for others. The fact they’ve shifted the work to their own servers and kept the ops team suggests it was the wrong sort of workload to be in the cloud in the first place.
For a while there was an obsession with moving everything to the cloud, and that was always going to be an expensive mistake in a number of different ways. Hopefully, as the hype dies down more nuanced decisions will be made. There’s a whole gamut of options between all in the cloud and all in the data centre, and when people jump straight from one end to the other I’m put in mind of Hamlet’s quote “There are more things in heaven and earth, Horatio, / Than are dreamt of in your philosophy.” Understand your workload, understand your business’ future plans and their needs, and then make a plan, considering all the tools at your disposal.










